Apple Microarchitecture Research by Dougall Johnson M1/A14 P-core (Firestorm): Overview | Base Instructions | SIMD and FP Instructions M1/A14 E-core (Icestorm): Overview | Base Instructions | SIMD and FP Instructions
This is an attempt at microarchitecture documentation for the CPU in the Apple M1, inspired by and building on the amazing work of Andreas Abel, Andrei Frumusanu, @Veedrac, Travis Downs, Henry Wong, Agner Fog and Maynard Handley. This documentation is my best effort, but it is based on black-box reverse engineering, and there are definitely mistakes. No warranty of any kind (and not just as a legal technicality). To make it easier to verify the information and/or identify such errors, entries in the instruction tables link to the experiments and results (~35k tables of counter values).
Firestorm is the high-performance microarchitecture used by the four P-cores in the M1.
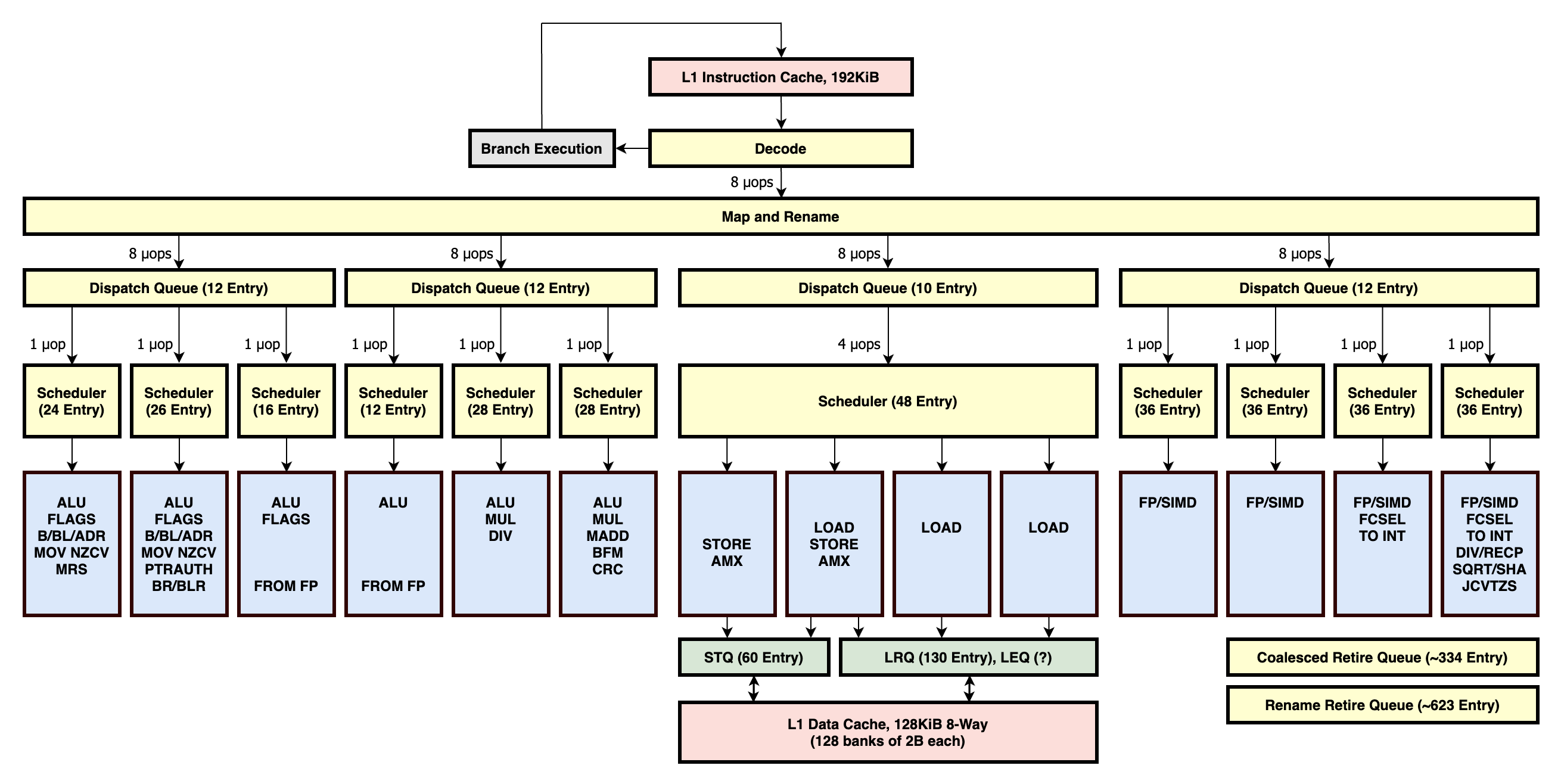
As instructions are executed, they are mapped to operations inside the processor. Typically, an instruction is decoded to one or more uops, each uop is mapped and renamed and placed into a dispatch queue. These uops are then dispatched from the queue to a scheduler. When the uop's input operands are ready, it issues from the scheduler, and is executed. After execution, it is marked as completed in the reorder buffer. Completed entries in the reorder buffer are then released in order.
This work focuses on measuring each instruction's uops and issues.
Uops count towards the "pipeline width" limit of 8 uops per cycle, and are measured
using the RETIRE_UOP counter. Issues count towards the "execution unit"
limits (one issue per unit per cycle), and can be measured using the documented SCHEDULE_UOP
counter. Three undocumented counters measure issues to the integer, load/store, and simd units separately,
so these values are provided in the instruction tables.
All instructions have at least one uop, and most instructions have the same number of issues as uops,
but some have fewer (e.g. nop, ldp, and fused instructions). On the other
hand, some instructions have more issues than uops, e.g ALU operations with an optional shift or
extend (which allows Firestorm to sustain 11 issues per cycle in contrived cases).
I use the name "units", but these may also be refered to as "ports" or "pipes".
Integer units: 1: alu + ubfm/sbfm + flags + branch + adr + msr/mrs nzcv + mrs 2: alu + ubfm/sbfm + flags + branch + adr + msr/mrs nzcv + indirect branch + ptrauth 3: alu + ubfm/sbfm + flags + mov-from-simd/fp? 4: alu + ubfm/sbfm + mov-from-simd/fp? 5: alu + ubfm/sbfm + mul + div 6: alu + ubfm/sbfm + mul + madd + crc + bfm/extr Load/store units (up to 128-bit loads and stores, including address generation with shifts up to LSL #3): 7: store + amx 8: load/store + amx 9: load 10: load SIMD units: 11: fp/simd 12: fp/simd 13: fp/simd + fcsel + to-gpr 14: fp/simd + fcsel + to-gpr + fcmp/e + fdiv + frecpe + frsqrte + fjcvtzs + ursqrte + urecpe + sha
Certain instructions are able to issue as one uop if they appear consecutively in the instruction stream.
adds/subs/ands/cmp/tst + b.cc (complete fusion when fused instructions read no more than 4 registers per 6 instructions)add/sub/and/orr/eor/bic/etc. + cbnz/cbz (usually fused, if destination matches cbz operand. also works with instruction variants that set flags)aese + aesmc (usually fused if operands match pattern "A, B ; A, A")aesd + aesimc (usually fused if operands match pattern "A, B ; A, A")aese/aesd + eor (usually fused if operands match pattern "A, B ; A, A, C" or "A, B ; A, C, A")pmull + eor (usually fused if operands match pattern "A, B, C ; A, A, D" or "A, B, C ; A, D, A")amx + amx (excluding loads and stores - probably fuses to something like a stp)Branch fusion does not work with implicit shift or extend, nor instructions that read flags (like adc)
Other tested patterns are not fused, including adrp + add, mov + movk, mul + umulh, and udiv + msub.
Certain instructions do not need to issue:
mov x0, #0 (handled by renaming, as is 32-bit version)mov x0, x1 (usually handled by renaming, 64-bit version only)mov x0, #123 (handled by renaming at a max of 2 per 8 instructions, both 32-bit and 64-bit. Includes all tested immediate "mov" aliases e.g. bitwise/movz/movn)movi v0.16b, #0 (handled by renaming, including other types)mov v0.16b, v1.16b (usually handled by renaming. Includes other full-width types e.g. v0.8h but not v0.8b)nop (never issues)b (unconditional branch never issues)Other tested instructions are not eliminated, including adr/adrp, mov w0, w1 and mov x0, xzr.
Several instructions have latencies that aren't adequately described in the instruction tables:
Firestorm has a pipeline width of eight instructions per cycle.
These numbers mostly come from my M1 buffer size measuring tool. See also my blog post Apple M1: Load and Store Queue Measurements.
Firestorm uses an unconventional reorder buffer, which I described as a ~330 entry "coalesced retire queue" and a ~623 "rename retire queue" (equivalent to a "Physical Register Reclaim Table").
Firestorm coalesces uops into retire groups, which all retire together. A retire group may contain up to seven uops.
Uops which can fail before retiring (such as memory accesses) must appear at the start of a group, and uops that can fail after retiring
(such as conditional branches) must appear at the end of a group. Groups of seven uops are only observed for eliminated instructions,
such as nop and mov with issuing uops limited to roughly four per group. The coalesced retire queue consists of
~330 such groups. This allows an out-of-order window of just over 1000 (contrived) instructions that issue, or over 2200 nop
instructions.
Any time an architectural register is written, that write must be retired (regardless of whether the instruction is eliminated).
This is tracked in a separate structure, called the "rename retire queue", which allows for up to ~623 renames. (For some examples:
cbz or str do not require entries, add and mov need one entry,
and adds or ldp need two entries.)
I use retirement to refer to an instruction's entry in the reorder buffer being released. However, as I've described in a blog post, loads and stores may commit out-of-order if they are non-speculative. This has some interesting implications. In particular, once a store has "completed", the architectural state must have advanced past that point.
Retirement-rate is measured at up to eight coalesced retire queue entries per cycle, or up to sixteen rename retire queue entries per cycle.